The Future Belongs to Specialized Experts: Why AI Isn’t One-Size-Fits-All.


Imagine you’ve just been asked to integrate AI into your product—one that needs to do it all: predict user churn, handle legal questions, parse medical data, and even produce marketing copy. You might initially look at a single, general-purpose Large Language Model (LLM) and think, “This should cover everything.” But as a product leader consuming this technology, you may soon discover that “bigger” AI doesn’t always mean “better” AI. One giant model can become unwieldy, expensive, and may still fail to deliver the specialized outcomes your users expect.
In this post, we’ll explore why relying on a single, all-purpose LLM often falls short, and how embracing a Mixture of Experts (MoE) approach—even if you’re sourcing your AI from third-party vendors or various open-source solutions—can improve performance, accuracy, and cost-effectiveness. We’ll walk through:
- Why Bigger Isn’t Always Better – How mega-models can be both inefficient and inadequate for specialized needs.
- What Mixture of Experts Actually Is – A quick look at the concept and why it replicates real-world expertise.
- How MoE Compares to RAG (Retrieval-Augmented Generation) – Highlighting differences when RAG is layered on a single model vs. on a specialized set of experts.
- Key Benefits for Product Leaders – Why you should consider MoE when integrating AI features into your product.
- Incorporating MoE into Your AI Strategy – Practical steps to leverage specialized experts, whether you build or source them externally.
By the end, you’ll see why the industry is moving towards MoE due to its increased agility and cost-effective way of serving diverse needs.
When Bigger Isn’t Always Better
If you’ve explored general-purpose LLMs like GPT-4 or Gemini, you know they’re trained on vast datasets covering a wide array of topics. That’s great for broad knowledge, but not always ideal for specialized tasks. For instance, a healthcare analytics tool might need precise medical terminology understanding, while legal contract analysis requires deep knowledge of case law and regulations.
- Mounting Complexity: Using a single massive LLM for every feature can bloat costs. Each new domain requires either more fine-tuning or additional engineering work to reduce errors.
- Diminishing Returns: Even after extensive fine-tuning, the improvement for niche tasks might be marginal, failing to meet the specialized standards your users or stakeholder’s demand.
- Risk of Generic Responses: Large models can produce “almost right” answers, which might suffice for everyday questions but falter in high-stakes scenarios like financial projections or healthcare diagnostics.
Rather than pushing a general-purpose LLM to its limits, you might benefit from an MoE system that taps into multiple specialized models. This shift parallels how, in a real organization, you hire different professionals—lawyers, accountants, engineers—rather than expecting one “super employee” to handle everything.
Mixture of Experts: A More Human Approach
Mixture of Experts (MoE) tackles specialization head-on. Instead of one do-it-all model, you have a suite of smaller, domain-focused models. For example:
- Finance Expert: Specially trained on balance sheets, stock filings, and financial regulations.
- Medical Expert: Tuned for interpreting clinical data, research papers, and medical jargon.
- Legal Expert: Geared toward contracts, case law, and compliance guidelines.
Won’t this make it difficult when choosing the right model? That’s where the routing layer comes in. A routing layer directs each query to the right expert—like a dispatcher sending a caller to the correct department. Only the relevant model is activated, saving compute cycles and improving domain accuracy.
Real-World MoE Examples
- Google’s GLaM: Early research that demonstrated efficiency by assigning different language tasks to specialized “experts.”
- BloombergGPT: A financial LLM specifically tuned to handle Bloomberg’s data, outperforming general-purpose models in finance-related tasks.
- Harvey AI: A specialized legal model, trained on case law and regulations, offering precise contract analysis that generalist LLMs often miss.
How MoE Differs from RAG on a Monolithic Model
Many product leaders see Retrieval-Augmented Generation (RAG) as a way to improve LLM accuracy. RAG fetches domain-specific documents from a knowledge base and feeds them into a large, often general-purpose models. This can help, but it doesn’t inherently address the limitations of a single broad model:
- Shallow Integration vs. Deep Specialization
- RAG (Generalist Model): The base model’s broad training may overshadow domain documents, leading to surface-level or confused interpretations.
- MoE: Queries go to a model inherently trained on that domain, ensuring deeper, more consistent understanding without having to sift through irrelevant general knowledge.
- Risk of Hallucinations
- RAG (Generalist Model): The monolithic model can blend retrieved data with its own biases, generating plausible but incorrect answers.
- MoE: Each expert’s narrower scope cuts down on random “inventions,” as it’s less likely to mix unrelated facts.
- Overwhelming General Data vs. Curated Expertise
- RAG (Generalist Model): Strong general-purpose biases can wash out domain-specific nuances.
- MoE: The sub-model is built on carefully curated data for its domain, leading to more authoritative outputs.
- Routing vs. Retrieval
- RAG (Generalist Model): Essentially a single model using an external database.
- MoE: A routing layer picks the right expert. Each specialized sub-model can still incorporate RAG, but within a narrowly defined context.
Bottom Line: While RAG can help, it doesn’t fundamentally change a generalist model’s nature. MoE, however, relies on multiple purpose-built models, minimizing generic or shallow responses.
Using RAG with an MoE Expert
If your product needs frequent updates (e.g., new regulations, daily market data), you can combine RAG with a specialized MoE sub-model. For example, a finance expert model may still retrieve the latest SEC filings but interpret them through a domain-specific lens, reducing hallucinations and boosting interpretive accuracy. This hybrid approach merges the best of both worlds—up-to-date information layered onto a deeply specialized model.
Why MoE Used to Flounder—and Why It Works Now
MoE has been around for years, but early implementations were clunky. Routing queries optimally was challenging, and the overhead of maintaining multiple sub-models often outweighed the benefits. Today we see:
- Dynamic Routing: Models only activate when needed, avoiding wasted computation.
- Reinforcement Learning for Load Balancing: Systems learn to assign queries effectively, minimizing idle or overloaded experts.
- Knowledge Distillation: Large models “teach” specialized ones, jumpstarting their capabilities without massive ground-up training.
The technology has matured to a point where MoE’s operational gains now outweigh the setup complexity—especially for product teams that need specialized accuracy.
Key Benefits for Product Leaders
1. Greater Accuracy Where It Counts
When users demand precise, context-specific answers—like medical diagnoses, legal contract checks, or advanced financial projections—generalist models often stumble. MoE sub-models have domain knowledge baked in, leading to fewer “almost right” answers and more reliable solutions.
2. Efficiency and Cost Savings
MoE only spins up the experts you need rather than one giant, all-purpose model every time. This can significantly lower your AI infrastructure costs, as each query calls only its relevant sub-model.
3. Modular Flexibility
Each expert sub-model can be treated like a microservice. If you find a better legal AI provider, you can integrate it as your “legal expert” without retraining or replacing every other AI component.
4. Differentiated AI Experience
From a product perspective, you can market domain-targeted features—like specialized compliance checks or advanced financial modeling—as a premium tier. This sets you apart from competitors relying solely on general-purpose LLMs.
Incorporating MoE into Your AI Strategy
As a product leader consuming LLM technologies, you might wonder how to capitalize on MoE if you’re not building your own LLM from scratch. Here’s a roadmap to guide you:
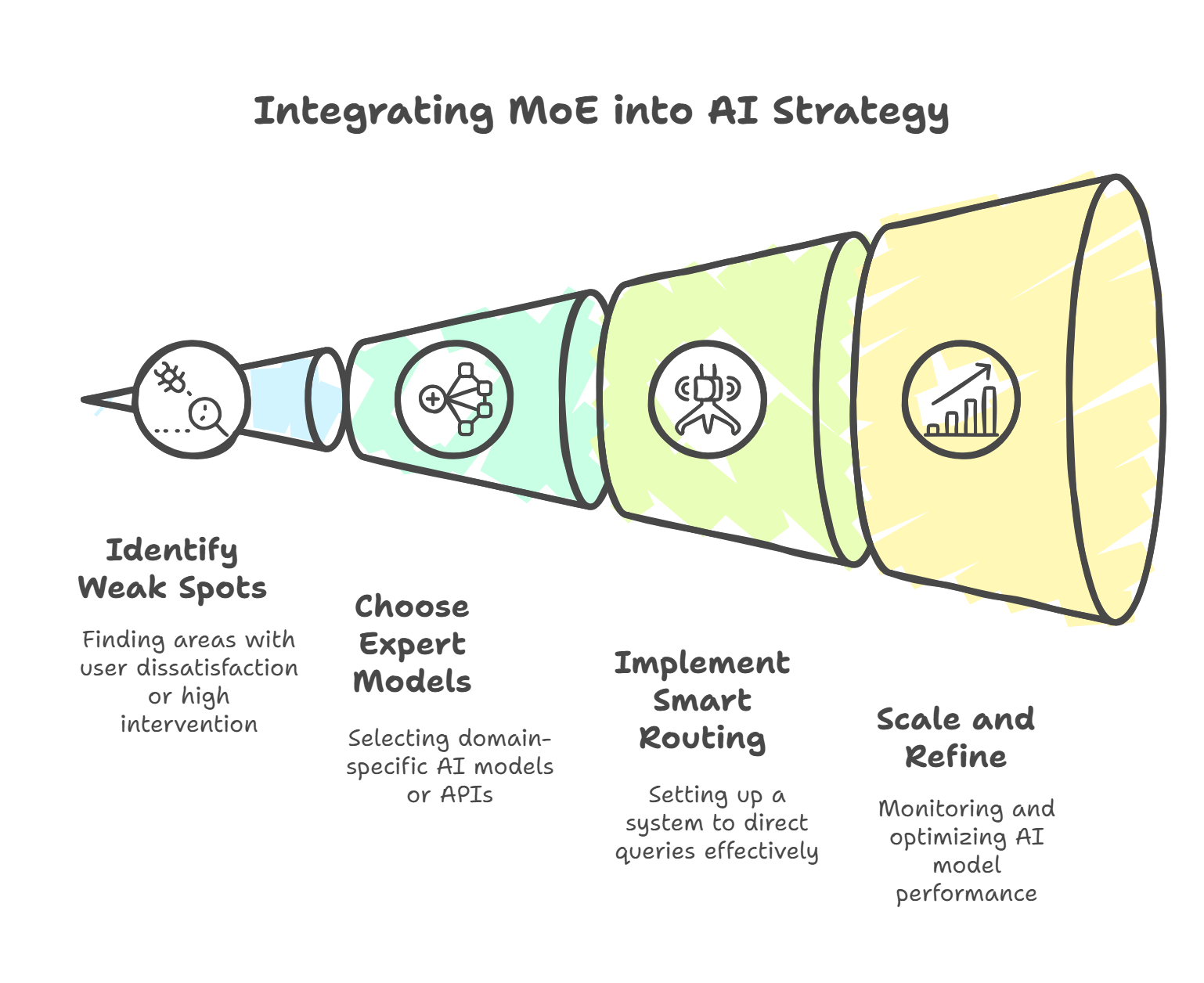
1. Assessment and Identification
- Find Existing Weak Spots: Look at your current AI-powered features. Which domains cause the most user dissatisfaction or require constant human intervention?
- Example: A CRM tool might struggle with sophisticated legal compliance checks, prompting you to add a specialized “legal model” from a trusted vendor.
- Evaluate ROI: Identify areas where specialized accuracy could significantly reduce costs or boost user trust (e.g., compliance, health advice, financial forecasts).
2. Choose or Assemble the “Expert Network”
- Vendor Sourcing: Shop around for domain-specific LLMs or AI APIs. For instance, a “financial statements” model from a fintech provider or a “medical triage” model from a healthcare-focused AI vendor.
- Example: An HR platform might integrate a specialized background-check AI as a sub-service, rather than relying on a single, monolithic model’s generic outputs.
- Prioritize High-Value Domains: Instead of adding every possible expert at once, start with the areas that directly impact your product’s core value proposition.
3. Implement Smart Routing
- Set Up a Dispatcher or Orchestrator: Think of this as your “air-traffic controller,” deciding which request goes to which vendor or sub-model.
- Example: A rules-based system can route “contract” queries to a legal AI vendor, while “balance sheet analysis” queries head to a finance AI.
- Iterate with Feedback: Over time, analyze usage patterns and user feedback. If the “legal AI” handles a high volume but shows latency, consider splitting tasks further or adding a second specialized vendor.
4. Scale and Refine
- Monitor Performance Metrics: Track each vendor’s accuracy, response times, and user satisfaction. Retire underperforming experts and onboard stronger alternatives.
- Example: If your specialized healthcare AI sees consistent errors in mental health queries, you might add a dedicated mental health sub-model or switch providers.
- Stay Flexible: As new regulations or technologies emerge, you can integrate additional sub-models without revamping your entire AI ecosystem. Think of each domain expert as a plug-and-play module.
Looking Ahead: A “Federation of Experts”
Over time, you might use multiple third-party specialized AIs—one for legal compliance, another for user sentiment analysis, another for finance—and orchestrate them through your product. This approach starts to resemble a “federation” of experts rather than a single monolithic system.
For product leaders, this not only ensures deeper, domain-specific accuracy but also opens up the potential for marketplace models, where new specialized AI services can be plugged into your ecosystem to cater to emerging user needs.
Final Thoughts: Embrace Specialization for a Competitive Edge
As a product leader integrating AI, you’re in a unique position to selectively adopt the best solutions for each domain. Relying on one massive, general-purpose LLM might seem simpler, but it can miss the depth and precision today’s users expect—especially for high-stakes or complex tasks.
By combining specialized MoE sub-models (sourced internally or via third-party APIs) with smart routing, you can lower costs, deliver targeted expertise, and craft a differentiated AI experience. Even if you employ RAG, layering it on a specialized expert will likely yield better results than piling context on top of a one-size-fits-all model.
Ultimately, the era of “one giant AI to rule them all” is giving way to a smarter, more flexible future. The MoE approach—whether through curated vendor solutions or open-source specialists—ensures each domain receives the focused attention it deserves. By embracing this shift, you’ll position your product to stand out in a rapidly evolving AI landscape, offering users real depth, reliability, and value.



